


👋 Pokrok v AI — newsletter č. 15
Patnácté vydání našeho newsletteru je tady a shrnuje informace o nových modelech od společností OpenAI a Google, o používání AI ve státní správě i o problémech se zobrazováním historických postav.


Vítejte v patnáctém vydání našeho newsletteru Pokrok v AI, ve kterém shrnujeme nejnovější poznatky a vývoj v oblasti používání umělé inteligence (AI), strojového učení (ML) a AI policy a regulace.
🎥 Nejnovější text-to-video model od OpenAI
OpenAI přišla s novým modelem Sora, který dokáže na základně textového popisu vygenerovat krátké video. Kvalita výstupu je vskutku neuvěřitelná a i přes to, že už jsme si na rapidní pokrok v umělé inteligenci hodně zvykli, působí stále jako velký krok kupředu.

Reakce na Sora na sebe nenechaly dlouho čekat — například americký režisér a producent Tyler Perry pozastavil $800M investice do expanze filmového studia a citoval tento AI model jako důvod:
"I was in the middle of, and have been planning for the last four years... an $800 million expansion at the studio…. All of that is currently and indefinitely on hold because of Sora and what I’m seeing. I had gotten word over the last year or so that this was coming, but I had no idea until I saw recently the demonstrations of what it’s able to do. It’s shocking to me."
Náš volný překlad: "Poslední čtyři roky jsem plánoval a pracoval na ... rozšíření našeho studia v hodnotě 800 milionů dolarů... To vše je v současné době pozastaveno na neurčito kvůli Sora a tomu, co vidím. Během posledního roku jsem se dozvěděl, že se to chystá, ale neměl jsem tušení, dokud jsem nedávno neviděl ukázky toho, co je model schopen udělat. Je to pro mě šokující."

Technický report k modelu Sora je sice docela skoupý na detaily, ale víme, že jde o diffusion model (stejně jako valná většina nejlepších generátorů obrázků dneška) a že používá architekturu zvanou Vision Transformer (ViT ve zkratce), která byla vyvinuta výzkumníky z Google Brain v Zürichu v roce 2021. Vědecký článek, který architekturu představil, má dnes již přes 30 tisíc citací a to je opravdu hodně. Každá z těchto citací je samostatný vědecký článek, který na Vision Transformer navazuje, nebo ho používá. Jde tedy o podobor-definující publikaci a zlatý standard ve zpracování obrazu.
💼 Státní správa pro století AI
AI proniká do všech oblastí života a rozhodně se nevyhne ani státní správě. Podle výzkumu britského Alan Turing Institute 22 % respondentů z řad britských úředníků aktivně používá generativní AI při své práci. Zároveň je ale používání AI ve státní správě citlivé, obzvlášť pokud by měla přístup k osobním datům či tajným informacím. I proto vydala britská vláda Rámec pro generativní AI ve státní správě jeho výsosti (Generative AI Framework for HMG, ano, doslovný překlad do češtiny zní zvláštně). Ten přichází s deseti základními principy pro zacházení s generativní AI ve státní správě a zdůrazňuje právě etický a bezpečnostní rozměr jejího použití.
Byť tak zapojení AI do fungování státní správy nějakou dobu potrvá, je určitě dobrým krokem, že se stát snaží nastavit jasná pravidla a podpořit její používání. V Británii totiž podle průzkumu ze serveru Politico (graf pod tímto článkem) 66 % respondentů věří, že regulátorům chybí znalosti efektivně regulovat nové technologie. Smysluplné využívání AI ve státní správě by toto vnímání mohlo zvrátit. Podle výzkumu organizace Behavioural Insights si totiž většina lidí myslí, že státní správa by měla používat AI k pomoci občanům a tato podpora se ještě zvyšuje, když jsou lidé vládním AI nástrojům vystaveni. Přestože podobná data k situaci v Česku chybí, není nepravděpodobné, že by se minimálně část české populace taktéž ráda vyhnula frontám na úřadech a místo toho se spojila se státním chatbotem.

🤡 Obrázkový generátor v modelu Gemini má problémy s charakteristikami historických postav
Generátor obrázků z textu, který je součástí modelu Gemini, dostal od uživatelů na internetu na frak kvůli očividným a velice vtipným nepřesnostem v reprezentaci genderu a etnicity historických postav. Situace dokonce došla tak daleko, že seniorní vice-prezident Googlu publikoval omluvný blog post s titulkem: Gemini image generation got it wrong. We'll do better.
Ve zkratce šlo nejspíše o to, že v rámci reprezentace spektra genderu a etnicity mezi obrázky generovaných lidí byl prompt, který model dostával, modifikovaný tak, aby různorodost preferoval. Problém ale nastal, když chtěl člověk například vygenerovat obrázek vikinga, papeže, nebo německého vojáka ze 40. let 20. století, u kterých existují jasná očekávání pokud jde o vzhled.
Němečtí vojáci z roku 1943 podle Gemini:

Vikingové podle Gemini:

Podle našeho názoru nejde o žádný velký technický problém a je velice pravděpodobné, že množství negativní zpětné vazby, kterou Google dostal, nejspíše povede k citlivějšímu řešení.
💎 Malý ale výkonný bratříček Gemini jménem Gemma
Google publikoval dva nové, state-of-the-art “velké” jazykové modely jménem Gemma, které jsou malými bratříčky velkých modelů Gemini. Zatímco největší z modelů rodiny Gemini, Gemini Ultra, poráží v mnohých testech i GPT-4 a má navíc obrovskou délku kontextu a schopnost analyzovat nejen text a obrázky, ale také videa, modely Gemma soutěží spíše s open-source alternativami od společností Meta nebo Mistral. Vrací také Google do hry v klání otevřených modelů a to rovnou s velkou slávou.

Gemma přichází ve dvou velikostech: 2B (= 2 miliardy trénovatelných parametrů, ~ 2 miliardy “synapsí” v umělém mozku tohoto modelu, což odpovídá asi 2 biologickým včelám) a 7B. Obě velikosti modelu přicházejí ve své původní, před-trénované formě a ve formě, která je dotrénovaná v postupování podle instrukcí a tudíž vhodnější pro praktické použití. Google taktéž publikoval sadu nástrojů pro dodatečné trénovaní těchto modelů přímo jejich uživateli, což výrazně snižuje bariéru pro jejich použití v rozličných doménách.
Gemma 2B a 7B jsou nejspíše nejlepšími (nebo minimálně jedněmi z nejlepších) jazykových modelů ve své “váhové” (nebo spíše parametrové) třídě v porovnání s ostatními otevřenými modely. Zároveň mohou obě verze běžet na laptopu nebo stolním počítači a člověk si pro jejich využití nemusí pronajímat nákladné grafické karty (GPUs) přes cloud.
(Technické detaily: Zajímavým rozdílem proti ostatním otevřeným modelům může být například nestandardně velký slovník, který se používá k takzvané tokenizaci vstupního textu do formy, kterou pak jazykový model přímo vnímá. Tokenizace funguje tak, že vstupní text rozseká na menší jednotky (tokeny), které mohou být vše od jednotlivých znaků (“A”, “B”), po částí slov (“tortoise” by byla tokenizována jako “t”, “or”, a “toise”), až po celé skupiny slov (“SolidGoldMagikarp”). Skvělé video, vysvětlující tokenizaci, před pár dny publikoval na YouTube slavný AI výzkumník a veterán Stanfordu, Tesly a OpenAI Andrej Karpathy (Standu v prváku na Stanfordu učil strojové vidění!). Gemma používá slovník o 256 tisících slovech, zatímco LLaMa jen o 32 tisících a otevřené modely Pythia o 50 tisících. Větší slovník je lepší pro použití u modelů, které jsou navrženy pro fungování ve více jazycích zároveň, což je nejspíše něco, v co Google doufá díky svému globálnímu dosahu a uživatelské základně.)
Před dvěma týdny také Google představil vylepšenou verzi svého nejlepšího multimodálního/jazykového modelu Gemini, Gemini 1.5, která využívá Mixture of Experts (MoE) architekturu, jenž je efektivnější a používaná (podle toho, co se říká na internetu) v modelu GPT-4. Největším zlepšovákem a něčím, co může odemknout úplně nové typy použití modelu, je ale jeho obrovské kontextové okno dlouhé až 1 milion tokenů. Pro představu: román Velký Gatsby by se do něj vešel 15x a odhadem jde o délku všech knih série Harry Potter.
🎭 Velké modely umí trochu hackovat
Vědci z University of Illinois Urbana-Champaign (kterou asi málo lidí v Česku zná ale například v žebříčku QS World University Rankings se letos umístila na 64. místě proti 248. místo Karlovy univerzity — Amerika má hodně dobrých univerzit) publikovali studii, ve které ukazují, že velké modely jako GPT-4 umí použít sofistikované techniky k hackování jednoduchých webových stránek. Konkrétně říkají, že:
“show that LLM agents can autonomously hack basic websites, without knowing the vulnerability ahead of time.”
Volný překlad: na velkých jazykových modelech postavení agenti umí hackovat základní webové stránky a to bez předchozí znalosti toho, jakou konkrétní slabinu stránka bude mít
Tento výzkum přispívá ke konkrétním důkazům toho, že velké jazykové modely mohou v budoucnosti umožnit špatným aktérům v doméně programování. Lidé o tomto sice spekulovali, ale přímých ukázek zatím bylo málo.
🔥 Samořídící Waymo zapáleno vandaly v San Franciscu
V neděli večer, během oslav nového lunárního roku, zničilo a zapálilo několik vandalů v San Franciském Chinatown samořídící elektrické vozidlo Waymo. Podle videí na X/Twitteru nejprve vandalové auto zablokovali, pak mu rozbili okna a posprejovali ho, a nakonec do něj hodili hořící pyrotechniku, od které auto vzplálo. Není jisté, do jaké míry šlo o promyšlený odpor proti samořídícím vozidlům, potažmo big tech, a nakolik o náhodný akt vandalismu — osobně se ale podle fotek a videí přikláníme k druhé možnosti.
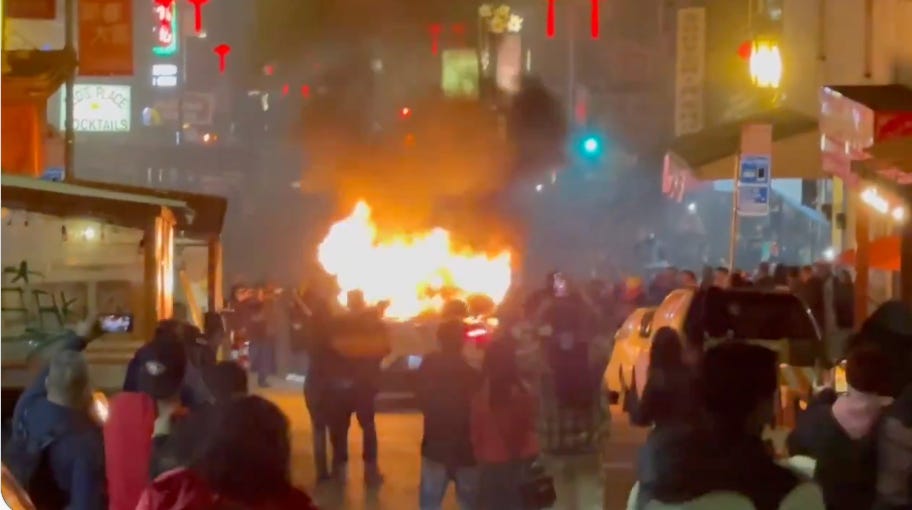
Ten samý den Standa v San Franciscu dvěma autonomními vozidly Waymo jel a jejich počet v ulicích se opticky určitě zvyšuje. Je čím dál tím běžnější vidět jednotlivce a skupiny lidí, kteří těmito auty po městě jezdí. Jak jsme psali v předchozím newsletteru, tak počet majetkových pojistných událostí je na kilometr pro vozidla Waymo 4-krát nižší než pro porovnatelné lidské řidiče a náš osobní pocit z cest s nimi je určitě bezpečnější než u typického řidiče Uberu — na rozdíl od nich třeba dodržují maximální povolenou rychlost a zastavují na stopkách. Další potenciální výhodou samořídících vozidel, o které jsme zaznamenali diskuze na X, je v jejich případě neexistující strach z nechtěné pozornosti ze strany řidiče, například při nočních cestách domů.
⚡Rychlé odkazy a myšlenky
🇻🇦 Papež se bojí, že se AI stane multiplikátorem nespravedlnosti a nerovnosti, říká jeho AI poradce.
💸 Stability AI (kde Standa dříve vedl vývoj jazykových modelů) prodala startup Clipdrop, který sama nedávno koupila, společnosti Jasper AI.
🚨 Meta má v plánu začít označovat AI generovaný obsah sdílený na Facebooku, Instagramu, and Threads.
㊍ Článek o tom, jak automatické překládání ovlivňuje kvalitu obsahu na internetu podle nového výzkumu Amazon Web Services.
🖼️ Stability AI uveřejnila novou verzi svého text-to-image modelu, Stable Diffusion 3, která je dobrá v generování textu a kvalitou se zdá minimálně porovnatelná s ostatními nejlepšími modely
Líbilo se vám patnácté vydání newsletteru Pokrok v AI? Odebírejte ho přímo do vaší emailové schránky a podpořte tím naši práci!
Můžete ho také sdílet s přáteli na sociálních sítích.
Napsali Stanislav a Kristina Fort.