


👋 Pokrok v AI — newsletter č. 2
Druhé vydání newsletteru informující o nejnovějším vývoji ve vytváření a používání umělé inteligence a strojového učení.

Vítejte v druhém vydání mého newsletteru Pokrok v AI, ve kterém shrnuji nejnovější poznatky a vývoj v oblasti používání umělé inteligence (AI) a strojového učení (ML).
Model CICERO z Meta AI hraje Diplomacii na lidské úrovni
Umělá inteligence CICERO z Meta AI se naučila hrát komplikovanou deskovou hru Diplomacie na lidské úrovni. Diplomacie je hra pro několik hráčů, kteří soutěží v ovládání území na mapě Evropy před 1. světovou válkou. Cílem je ovládnout většinu území skrze strategii, taktiku, a typicky tajná vyjednávání mezi jednotlivými hráč. Diplomacie byla dlouho považována za jednu z nejobtížnějších her pro umělé inteligence, protože narozdíl od šachů (AI vyhrávají od let 1996-1997, slavný zápas Gary Kasparov vs IBM Deep Blue) či Go (AI vyhrávají od roku 2016, slavný zápas Lee Sedol vs DeepMind AlphaGo) závisí úspěch v Diplomacii na vyjednávání a strategickém klamu v přirozeném jazyce (jako je například angličtina). Úspěch systému CICERO v Diplomacii (v “blitz” verzi, kde kola trvala pouze 5 minut, narozdíl od typicky delší, hlubší diskuze) je na jednu stranu velkým pokrokem umělé inteligence a strojového učení jako oboru. Na druhou stranu jsou ale někteří výzkumníci nervózní z toho, že jde o výsledek explicitně vyžadující od umělé inteligence strategické schopnosti a úmyslný strategický klam ve vztahu k ostatním lidským hráčům.

Youtuber Rob Miles, který vytváří zajímavá a informačně bohatá videa o problémech v bezpečnosti umělé inteligence (AI safety), v jednom z videí před 4 lety (!) uzavírá svoji prezentaci slovy: “Beating humans at Go is a pretty big deal. But we’re really in trouble when AI beats us at ‘Diplomacy”.
CICERO je kulminací tříletého výzkumného projektu, jehož cílem bylo vytvořit AI, která dokáže vézt strategická vyjednávání v přirozeném jazyce lépe než člověk. Klíčem k výhře je vytvořit důvěru mezi hráči v prostředí, které aktivně důvěru podrývá. I přes menší popularitu Diplomacie mezi veřejností, oproti například šachům, byla Diplomacie oblíbenou hrou prezidenta USA Johna F. Kennedyho. Demis Hassabis, CEO a zakladatel AI společnosti DeepMind (která zvládla vytvořit model porážející lidi ve hře go nebo skládající proteiny), býval šampionem v Diplomacii (stejně jako v dalších deskových hrách).
Během 40 her s 82 lidskými hráči, které celkově obsahovaly 5,277 zpráv a 72 hodin herního času, získal systém CICERU více než dvojnásobné skóre průměrného hráče a umístil se ve vrchních 10 % účastníků. Jde o první AI systém, který hraje Diplomacii na lidské úrovni.
Zdrojový kód a trénované modely jsou k dispozici online na GitHubu. Několik her s komentářem zkušeného hráče je také k dispozici na Youtube.

Meta AI model Galactica stažen po 3 dnech online
Jazykový model Galactica, o kterém jsem psal v první vydání newsletteru ✨ Pokrok v AI ✨ , byl již po 3 dnech veřejného přístupu stažen z webové stránky. Na místě textového pole, ve kterém bylo ještě před týdnem s modelem možné mluvit, je teď krátká zpráva: “Thanks everyone for trying the Galactica demo. Read more about the research below,” která odkazuje na PDF vědeckého článku, který vyšel společně s modelem. Meta se pravděpodobně rozhodla model stáhnout po té, co množství výzkumníků a lidí z širší veřejnosti ukázalo, že AI dává často minimálně zavádějící a často i chybné výsledky na relativně jednoduché otázky. Stažení modelu Galactica je dalším z řady problémů, které provázejí Meta AI v jejím veřejném použití velkých jazykových modelů. Ukazuje také, že i přes velký potenciál této technologie zbývá ještě velké množství otázek, která je potřeba rozřešit před jejím masivním rozšířením.
Stanford testuje a hodnotí jazykové modely
Výzkumní z Institute for Human-Centered AI (HAI) na Stanfordské univerzitě vydali porovnání 30 prominentních velkých jazykových modelů přes široké spektrum scénářů a metrik, což jim umožnilo srovnat jejich schopnosti, problémy a rizika na standardizovaných úlohách. Jazykové modely jsou často testované na těch samých datasetech, ale se změnami, které způsobují, že je občas těžké říci, který model je lepší. Velká část toho nejzajímavějšího v chování umělých inteligencí je také často obtížně měřitelná na standardních úlohách, které byly historicky používány. Tento článek je dalším pozitivním výsledkem z akademické strany pomyslné dělící linii mezi AI výzkumem v technologických firmách, které už několik let stojí v popředí nejnovějšího (i čistě akademického!) výzkumu AI, a univerzitami, které díky limitovanému výpočetnímu výkonu, expertíze a inženýrskému talentu často hrají druhé housle.
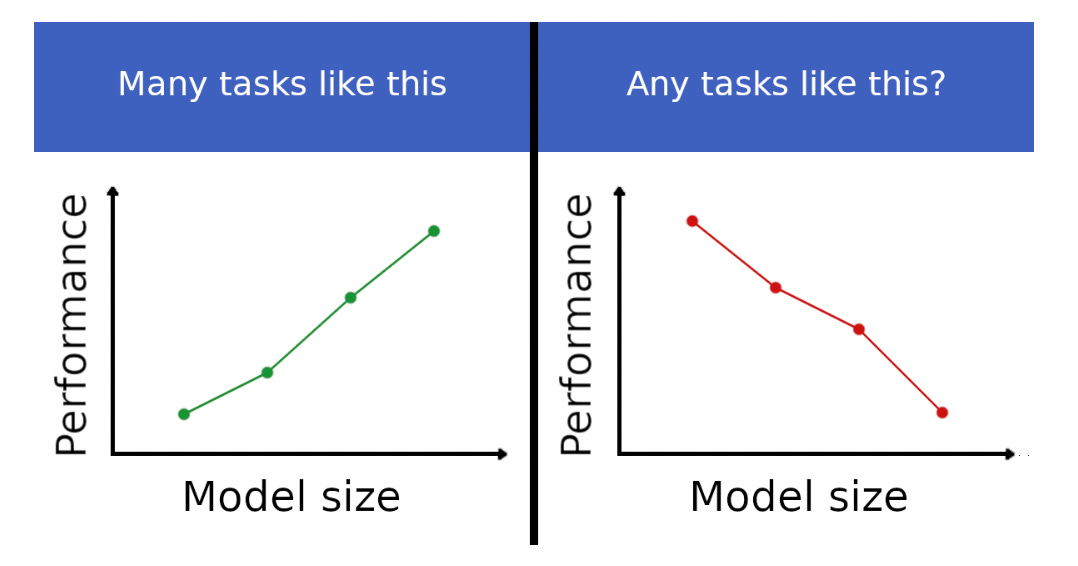
Inverse scaling prize — v čem jsou velké AI horší než malé?
Skupina výzkumníku vypsala soutěž Inverse scaling prize, ve kterém vyzívá AI komunitu, aby našla úlohy, na kterých se AI s velikostí zhoršují. Čím větší velký jazykový model (podle počtu trénovatelných parametrů, které by se daly přirovnat k synapsím v biologických neuronových sítích, nebo množství dat, na kterých se trénuje), tím jsou schopnosti AI lepší a chování inteligentnější. Tento trend byl shrnut do takzvaných scaling laws, které jsou při nejlepším empirická pozorování a ne zákony, na které jsme zvyklí například z fyziky. I přes jejich velmi empirický charakter se ale zdá, že jejich predikce platí, a že čím větší model, tím předvídatelně lepší je. V prvním a druhém kole Inverse scaling prize, jejichž příspěvky jsou už bohužel uzavřeny, bude rozděleno celkem $250,000 (přibližně 6 milionů korun) v cenách pro vítězné návrhy. V druhém kole jsem také jedním z porotců!
Rychlé odkazy:
More is different (1972, P. W. Anderson, nositel Nobelovy ceny za fyziku): Slavná esej, jejíž hlavní argument je, že k pochopení systému se musíme pohybovat na té správné úrovni abstrakce, na které jsou efekty a chování, o jejichž vysvětlení se pokoušíme, nejpřirozeněji přístupná. Například k vysvětlení chování vln na hladině jezera není dobrý nápad začít od kvarků a kvantové teorie pole. Tento pohled, který se částečně liší od filosofického redukcionismu, je čím dál tím populárnější mezi lidmi co pracují na pochopení AI.
GPT-3 text-davinci-003 je na světě! Nová verze nejslavnějšího velkého jazykového modelu GPT-3 z OpenAI je k dispozici veřejnosti přes webové rozhraní a API. Jan Leike, který v OpenAI vede AI Alignment (v ekvivalentním týmu pracuji v Anthropic AI) říká, že davinci-003 je “more aligned” (aligned zde znamená, že chování AI odpovídá lidským hodnotám, preferencím a očekáváním) a mnoho expertů se domnívá, že minimálně částečně využívá techniku RLHF (reinforcement learning on human feedback, detaily například v tomto článku).
Generativní AI Stable Diffusion vychází ve své druhé verzi. Obrázky z ní vypadají ještě lépe, než v první verzi. Vývojáři zároveň přidali podporu pro množství dalších nástrojů.


Líbilo se vám druhé vydání newsletteru Pokrok v AI? Odebírejte ho přímo do vaší emailové schránky a podpořte tím mojí práci!
Můžete ho také sdílet s přáteli na sociálních sítích.
Napsal Stanislav Fort, editovala Kristina Šůsová.
Nevím jestli si to pamatuju z Lexova podcastu se spoluautorem CICERA ( https://youtu.be/2oHH4aClJQs ) nebo někde jinde, ale ono to strategicky nelže. V té hře je lhaní i dlouhodobé nevýhodné, protože ostatní hráči ti pak nevěří, což je velký handicap. Nicméně si ta ai může na základě nové situace přehodnotit a udělat něco jiného, než co dřív slíbila.
A taky tam mluví o tom, že si nemyslí, že to strategicky plánuje. Spíš prostě umí skvěle vyhodnotit stav a na základě naučených heuristik navrhnout docela dobrou akci. Tzn asi jako kdyz šachový velmistr normálního člověka porazí i když hraje jen první tah, co mu hodí intuice versus když provádí nějaký high level rozmýšlení, co přesně zahrát.
Co myslis, ze bude dalsi krok?
Je tohle validni intuice, nebo uplny nonsense:
Aktualne je pro ty modelu realitou ciste struktura jazyka. Nemaji data ani incentiv na to, aby jenom nevytvareli "smysluplne znejici" texty.
Prijde mi, ze jazyk hraje 2 role:
1) Signalizovani umyslu ostatnim
2) Sdileni a porozumeni vzajemnym modelum sveta
Je uzitecny rozpoznat, jestli jsou ostatni duveryhodni a pak cross checkovat signalizovani s realnym chovanim.
Pouziva se uz neco takoveho pri trenovani vic cilene, nez napriklad tady u Diplomacy?