


👋 Pokrok v AI – newsletter č. 31
Další vydání je tady, tentokrát s cílem prozkoumat, kdo vymyslel jazykové modely, jak ovlivní superinteligence geopolitiku, jestli AI projde Turingovým testem, a jak dlouhé úlohy AI sama vyřeší.


Vítejte ve třicátém prvním vydání našeho newsletteru Pokrok v AI, ve kterém shrnujeme nejnovější poznatky a vývoj v oblasti používání umělé inteligence (AI), strojového učení (ML) a AI policy a regulace.
💡 Kdo vymyslel jazykové modely?
Na X teď probíhala velká debata o tom, kdo vlastně vymyslel jazykové modely. Říkali jsme si proto, že se pokusíme o malou historickou retrospektivu do fundamentálních vědeckých článků a přístupů, které vydláždily cestu k dnešním velkým jazykovým modelům (LLMs).
Před sedmi lety, v červenci 2018, jel Standa Uberem do kanceláře Google Brain v Mountain View a četl si na první pohled příliš nezajímavý blog post s technicky znějícím titulkem: NLP's ImageNet moment has arrived. Zasvěceným ale našeptával cestu k velkým jazykovým modelům (dávno před ChatGPT). Jeho autorem byl německý výzkumník Sebastian Ruder a pro svůj příspěvek si zvolil dobře padnoucí podtitulek: Big changes are underway in the world of Natural Language Processing (v překladu: Ve světě zpracování přirozeného jazyka se dějí velké změny) — a velké změny opravdu přišly.
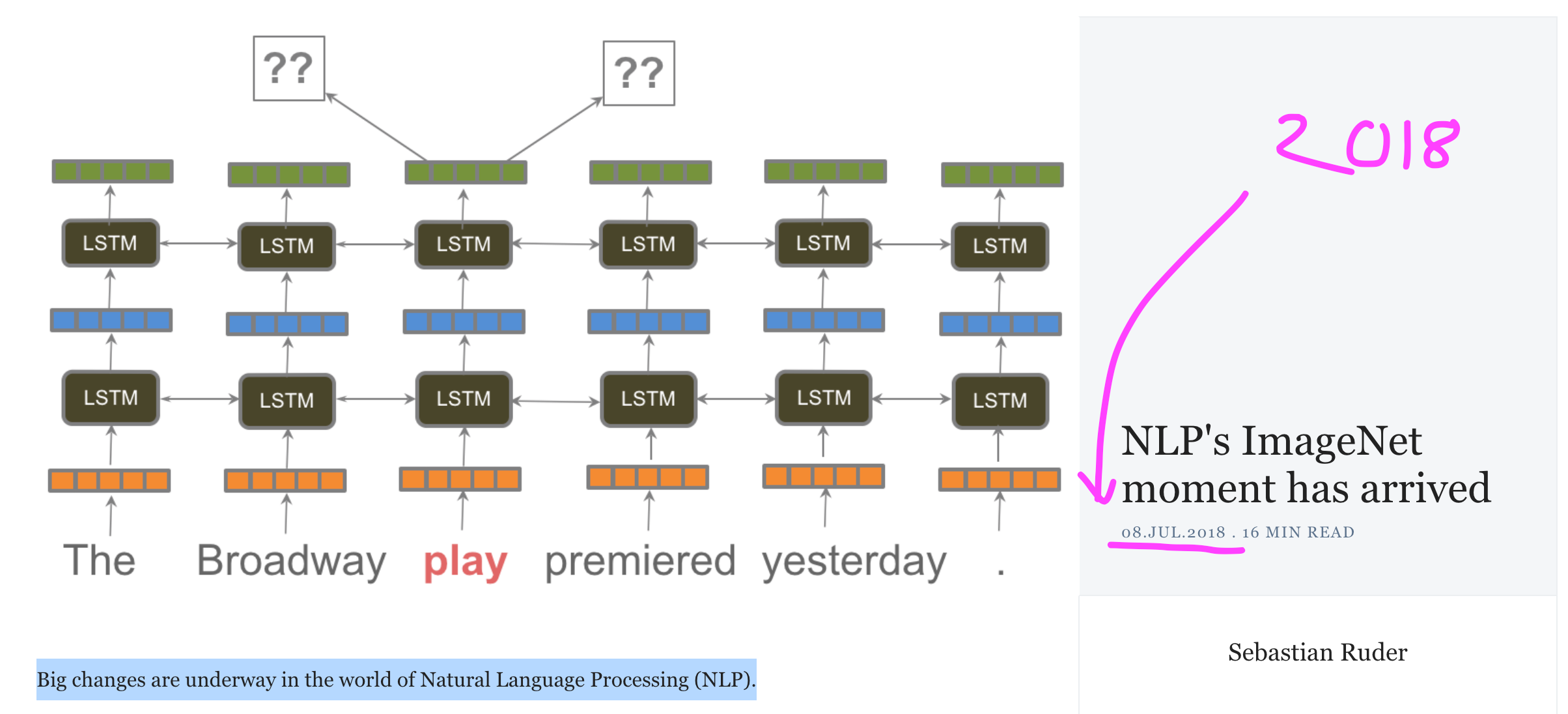
Terminologie
NLP je zkratkou pro Natural Language Processing, česky zpracování přirozeného jazyka. Obecně jde o to, jak naučit počítač pracovat s textem v lidském jazyce, jako je například čeština, angličtina nebo čínština, na rozdíl od jazyka počítačového, jako jsou třeba programovací jazyky C nebo Python.
ImageNet moment referuje k historickému posunu v druhé z hlavních domén strojového učené — počítačovém vidění, během kterého se strojově učící modely přestaly trénovat specificky na konkrétní úlohu (třeba na rozeznávaní čísel). Místo toho se model nejprve předtrénoval (“pretrain”) na velké datové sadě obrázků jménem ImageNet, který byly roztříděny do 1000 kategorií (například želva, útes, tank, bernardýn), a pouze poté se takzvaně doladil (“finetune”) na konkrétní úloze, jako je třeba rozeznávání číslic.
Ukázalo se totiž, že masivní obecný předtrénink, následovaný pouze krátkým dolazením na konkrétní úloze, funguje o hodně lépe než předchozí přístup. Obecné znalosti, který se model naučil z masivního předtréninku, totiž mohl snadno použít během dolazení na relativně malém množství dat. To samé se v roce 2018 poprvé začalo dít i v jazyce a byla to opravdu velká revoluce!
Starý přístup k jazyku — word2vec a mělký trénink
Pokud byla pravda, že se v jazyce opravdu objevil ImageNet moment, znamenalo to, že nemusíme trénovat zvlášť modely pro klasifikaci sentimentu tweetu, identifikaci jmen, nebo strojový překlad. Mohli bychom udělat jeden masivní dataset obsahující vše, využít toho, že tak získáme o hodně víc dat a že zároveň pro sebe navzájem nejspíš budou jednotlivé úlohy užitečné, a na konkrétní downstream (konečné) úlohy pak takto předtrénovaný model jen lehce, levně a rychle doladit.
Jak se dělalo zpracování jazyka před masivním předtréninkem? Bylo to těžké a z dnešní perspektivy to moc dobře nefungovalo! Předchozí přístupy fungovaly přibližně takto:
V roce 2013 několik vědců, mezi nimi Tomáš Mikolov (donedávna na ČVUT), Kai Chen, Greg Corrado, Jeffrey Dean (dnes hlavní vědec celého Googlu a jen s malou dávkou nadsázky Chuck Norris mezi programátory), Ilya Sutskever (bývalý hlavní vědec OpenAI), vytvořili word2vec. V roce 2014 zlepšili word2vec Jeffrey Pennington, Richard Socher (CEO AI vyhledávače you.com), Christopher D. Manning (slavný profesor NLP na Stanfordu — učil Standu první předmět na zpracování jazyka!) a vytvořili GloVe. Oba přístupy se dokáží naučit jednoduché vektorové reprezentace slov z velkého korpusu. Problémem je, že tyto reprezentace jsou takzvaně mělké, tedy neobsahují v žádném případě dostatek informací k tomu, abychom pomocí nich dokázali modelovat jazyk. Jsou ale skvělým prvním krokem.
Při řešení konkrétní úlohy (třeba klasifikace sentimentu tweetů) se první vrstva neuronové sítě typicky inicializovala z word2vec, GloVe, nebo obdobné mělce předtrénované reprezentace. Zbytek sítě se pak dotrénoval na úloze samotné, která měla z dnešního pohledu typicky velice málo dat. Word2vec byl potřeba právě proto, že toto malé množství dat by nestačilo k tréninku celé sítě a bylo tedy nutné sehnat informace odkud se dalo.
I přes to, že přístupy jako word2vec nebo GloVe byly historicky důležité pro strojové porozumění textu, měly zároveň katastrofickou limitaci — informace o slovech zakódovávaly jen do ekvivalentu úplně první vrstvy neuronové sítě, tedy vrstvy, která je nejméně zodpovědná za “abstraktní přemýšlení” a nejvíce podobná reflexivní reakci. V počítačovém vidění například první vrstvy neuronové sítě sledují pouze typy a orientace hran v obrázku (a to samé u zvířat, byla za to i Nobelova cena!), zatímco vrstvy hlubší uvažují o kontextu a objektech, které se v obrázku vyskytují.
Dnešní přístup = masivní předtrénink na všem
Pokud jde o to, kdo “vymyslel” současné velké jazykové modely (LLMs), velice dobrým kandidátem jsou Australan Jeremy Howard a právě výše zmíněný autor blog postu Němec Sebastian Ruder ve svém článku Universal Language Model Fine-tuning for Text Classification (v překladu Dolazování univerzálního jazykového modelu pro klasifikaci textu). Klíčový element, který autoři ukázali, byla právě možnost masivního předtréninku univerzálního modelu (teda modelu, který je vhodný pro všechny úlohy) a to tak, že takto trénovaný model se dá velice snadno doladit na konkrétní úlohu.

Ve vědeckém článku, ve kterém OpenAI představila GPT-1, tedy model, ze kterého se o několik let později stalo ChatGPT, se přímo píše:
The closest line of work to ours involves pre-training a neural network using a language modeling objective and then fine-tuning it on a target task with supervision. Dai et al. [13] and Howard and Ruder [21] follow this method to improve text classification. However, although the pre-training phase helps capture some linguistic information, their usage of LSTM models restricts their prediction ability to a short range.
Ve volné překladu:
Vědecká práce, která je nejbližší naší, zahrnuje předtrénování neuronové sítě pomocí modelování jazyka a její následné doladění na cílové úloze. Tuto metodu používá Dai et al. [13] a Howard and Ruder [21], kteří se snažili zlepšit klasifikaci textu. Nicméně i když fáze předtrénování pomáhá zachytit některé jazykové informace, jejich použití modelů LSTM limituje jejich schopnost predikce pouze na krátký kontext
Autoři, kteří představili GPT-1 (vedeni Ilyou Sutskeverem), sami říkají, že jejich práce navazuje na první pokusy s obecným předtréninkem velkého jazykového modelu. Reference Howard and Ruder [21] se odkazuje přímo na tento článek, který je tedy dost dobře možné považovat za první “velký” jazykový model dnešního typu.
GPT-1 ale zároveň zmiňuje, že jejich klíčovým zlepšovákem bylo použití takzvaného Transformeru — neuronové architektury (= typu propojení neuronů v umělém mozku), kterou vyvinuli výzkumníci v Google Brain v roce 2017 a představili v dnes již legendárním článku. Transformer samotný vznikl snahou zbavit se závislosti na velice špatně škálovatelných rekurentních neuronových sítích, které se typicky používaly, společně s word2vec, v předchozím NLP paradigmatu.
Dnešní jazykové modely stojí na velkém množství překvapivě velice iterativních zlepšováků — v podstatě nic v jejich genezi není při pohledu zpět revolučním krokem. V dnes již velmi známé zkratce GPT reprezentuje písmeno G slovo Generative, písmeno P Pre-trained, a písmeno T Transformer. Jméno samotné tedy ukazuje na dva proudy geneze dnešních LLMs: 1) Předtrénink na masivním množství dat, který se dá velice dobře vystopovat k článku Universal Language Model Fine-tuning for Text Classification a 2) architekturální průlom ve formě takzvaného Transformeru, který pochází z článku Attention Is All You Need.
👑 Kdo povládne AI?
Jedním z velmi vlivných textů za měsíc březen je rozhodně esej Superintelligence Strategy, kterou vydali ředitel Centra pro bezpečnost AI Dan Hendrycks, bývalý CEO Googlu Eric Schmidt a CEO ScaleAI Alex Wang. V rámci této eseje varují před nebezpečnou eskalací a místo toho navrhují nový systém založený na odstrašování (deterrence) — vzájemně zajištěné selhání umělé inteligence (mutually assured AI malfunction = MAIM). Jejich přístup je volně založen na realismu (z teorie mezinárodních vztahů) i teorii her.
Tento návrh je inspirovaný obdobným konceptem, který vzniknul během studené války mezi USA a SSSR — vzájemně zaručené zničení (mutual assured destruction = MAD). To stipuluje, že případný jaderný útok by vedl ke zničení jak útočící, tak i bráníc se strany. Hendrycks, Schmidt a Wang tvrdí, že to samé by se stalo, pokud budou s AI nebezpečně zacházet i aktuální světové mocnosti. Zároveň vyzývají k tomu, aby byla tato strategie doplněna i o snahu nerozšiřovat nebezpečné AI systémy do nebezpečných států (non-proliferation to rogue states) a zajištění vlastní konkurenceschopnosti, což má zabránit dosahování nadvlády jedné strany nad tou druhou.

Byť může mít tato esej dopad na americký přístup k “AI závodu” s Čínou, především kvůli prominenci jejích autorů, dostalo se jí také mnohé kritiky. Někteří říkají, že bez vzájemné dohody na tom, co je pro dané státy “nepřekročitelné”, je těžké dosáhnout stability. Jiní argumentují, že mezi AI a jadernými zbraněmi jsou podstatné rozdíly — vývoj AI za sebou například zanechává o mnoho méně stop, a tak by se mohl jednoduše odehrávat potají.
AI má už nyní silné implikace pro mezinárodní bezpečnost a je tak velmi zajímavé pozorovat, jak o dynamice mezi USA a Čínou různí aktéři veřejně přemýšlí. Byť může inspirace studenou válkou a “regulací” jaderných zbraní nabízet zajímavé modely, je nutné uvědomovat si fundamentální rozdílnost těchto technologií. Zatímco využívání Track II diplomacy (budování porozumění mezi nestátními aktéry, například mezi vědci) může být užitečné i pro AI, strategie založená MAD/MAIM aktuálně nepůsobí příliš přesvědčivě.
🧑🏼🎓 GPT-4.5 prošla Turingovým testem
Nový článek Large Language Models Pass the Turing Test (v překladu Velké jazykové modely procházejí Turingovým testem) od dvou výzkumníku z UC San Diego přesvědčivě demonstroval, že GPT-4.5 prochází Turingovým testem v nastavení, které se Turing sám představoval: účastník mluví zároveň s človek a AI a musí rozhodnout, kdo (co) je kdo (co).

Předchozí články ukazovaly, že GPT-4 prochází Turingovým testem v modifikované formě, kde účastníci mluví buď s AI nebo s člověkem, a musí rozhodnout, jestli se jedná o lidskou nebo umělou inteligenci. Takováto hra je nejspíše pro AI jednodušší. Nejnovější článek hodnotí AI v testu původní Turingově formy, kterou pionýr počítačové vědy představil v článku Computing machinery and intelligence (Výpočetní stroje a inteligence) v roce 1950:
The new form of the problem can be described in terms of a game which we call the 'imitation game.' It is played with three people, a man (A), a woman (B), and an interrogator (C) who may be of either sex. The interrogator stays in a room apart from the other two. The object of the game for the interrogator is to determine which of the other two is the man and which is the woman. The interrogator is allowed to put questions to A and B...
…
We now ask the question, 'What will happen when a machine takes the part of A in this game?' Will the interrogator decide wrongly as often when the game is played like this as he does when the game is played between a man and a woman? These questions replace our original, 'Can machines think?'
Volný překlad:
Novou podobu problému lze popsat jako hru, kterou budeme nazývat 'imitační hrou'. Hrají ji tři osoby, muž (A), žena (B) a tazatel (C), který může být obojího pohlaví. Tazatel zůstává v místnosti odděleně od ostatních dvou. Cílem hry pro tazatele je určit, který ze zbylých dvou je muž a který žena. Tazatel smí klást otázky A a B...“
…
Nyní si položíme otázku: „Co se stane, když se role A v této hře ujme stroj?“. Bude tazatel rozhodovat chybně stejně často, když se hraje takto, jako když se hraje mezi mužem a ženou? Tyto otázky nahrazují naši původní otázku: „Mohou stroje myslet?“.
GPT-4.5 bylo hodnocena jako “člověk” častěji, než lidský účastník samotný (>70% úspěch)! Open source modely od firmy Meta jménem Llama-3.1 byly od lidí v tomto testu nerozlišitelné (50% úspěch). Prastarý chatbot jménem ELIZA, který autoři používali jako spodní limit úspěšnosti pro porovnání, byl úspěšný jen v přibližně 20 % případů, tedy byl snadno odlišitelný od lidí a rozeznatelný od člověka.

Autoři ukazují, že když jazykové modely nenapromptují tak, aby se chovaly jako lidé, tak se jejich úspěšnost výrazně sníží. Koneckonců, velký jazykový model je nástroj veskrz univerzální a pouze díky promptování jsme mu schopni říci, jakou konkrétní úlohu má řešit a jakou roli plnit. To, že i bez takovéhoto promptu, je stále GPT-4.5 v některých z Turingových testů v článku nerozlišitelné od lidí, je velice překvapivé!
Zdá se, že Turingův test byl tedy skoro určitě pokořen! Turingův vhled operacionalizovat strojovou inteligenci jako imitační hru byl dekády napřed proti reálnému vývoji AI. Dnes, kdy jsme se k reálné AI hodně přiblížili, je ale vidět, že Turingův test sám o sobě není žádným diskrétním milníkem. Tento článek se zároveň zabýval testy, které trvaly pouze pět minut, takže je možné, že delší konverzace by dala lidem výhodu? I tak je neuvěřitelné, jak daleko jsme se dostali!
📏 “Moorův” zákon pro AI modely?

Výzkumná společnost METR publikovala skvělý vědecký článek, ve kterém se pokusila změřit rychlost zlepšování umělé inteligence v čase. Všichni sice tušíme, že AI se postupně zlepšuje, kvantitativní měření toho efektu je ale překvapivě těžké. Autoři se rozhodli, že jako metriku úspěchu použijí délku úloh, které umělé inteligence dokázaly řešit autonomně.
Například GPT-3 v roce 2021 dokázalo koherentně odpovědět na relativně komplikované otázky a napsat jednoduché odstavce textu — úlohy, které by člověku zabraly jednotky vteřin. Dnešní modely z vlastní zkušenosti dokážou řešit samostatně rozsáhlé programovací a vědecké problémy, které by lidem trvaly i desítky minut. Standa například rutinně používá Claude 3.7 Sonnet, Gemini 2.5 Pro a OpenAI o1-pro ke generování vědeckého kódu o stovkách řádek najednou, které by typicky trvalo několik desítek minut napsat a doladit.
Autoři zjistili, že umělé inteligence dokáží řešit čím dál tím delší úlohy, konkrétně se délka úloh, které zvládají, zdvojnásobuje přibližně každých 7 měsíců. Vztah, který se na logaritmickém grafu objevil, je hodně podobný takzvanému Moorově zákonu, který prvně vyslovil spoluzakladatel firmy Intel a který říká, že se počet tranzistorů na čipu zdvojnásobuje přibližně každé dva roky.
Moorův zákon byl původně vysloven na základě hrstky pozorování a nebylo jasné, jak dlouho bude platit. Stejně tak i zde existují pochybnosti ohledně toho, jestli bude trend pokračovat — proč by ale ne? Další validní kritikou je, že autoři článku vybrali úlohy, které reprezentují úzkou doménu softwarových problémů, jež se typicky vyznačují větší přímočarostí a jednoduchostí. To sice může být pravda, ale právě tyto úlohy mají disproporčně velkou ekonomickou hodnotu, takže to nemusí být tak velký problém, jak by se na první pohled mohlo zdát.
Nehledě na kritiky byl tento článek jedním z nejpreciznějších pokusů o kvantitativní měření rychlosti zlepšování AI v čase.
⚡Rychlé odkazy a myšlenky
🇮🇳 Jestli vás zajímá, co bude po pařížském AI Action Summitu, můžete si přečíst tento zajímavý příspěvek.
🚨 Podle některých testování to vypadá, že nová americká cla, která prezident Trump nedávno představil, generovala umělá inteligence. Pokud k tomu skutečně došlo, tak je to pravděpodobně první velký krok AI, který přímo ovlivní současnou geopolitickou situaci.
⏱️ Nová detailní esej o budoucnosti A(G)I byla uveřejněna na AI 2027 a stala se velkým předmětem diskuzí
🦙 Meta vydala rodinu modelů Llama 4. Největším překvapením je 10 milionů tokenů velké kontextové okno modelu Llama 4 Scout. 10 milionů tokenů je hodně! Všechny knihy o Harry Potterovi mají dohromady jen přibližně 1 milion slov.
🌟 Gemini 2.5 Pro – nový skvělý model od Google DeepMind, o kterém ale málo lidí ví, protože vyšel ve stejnou dobou jako OpenAI-trigrovaná Ghiblipokalypsa – je jako první model schopen netriviálního výsledku na USAMO 2025. Zároveň ale Google porušil svoje bezpečnostní závazky a tento model zveřejnil bez systémové karty, která by představila jeho testovací procesy apod. Tento příklad ukazuje, že bez vymahatelné regulace AI společnosti k dobrovolným závazkům trochu otupí.

Líbilo se vám třicáté první vydání newsletteru Pokrok v AI? Odebírejte ho přímo do vaší emailové schránky a podpořte tím naši práci!
Můžete ho také sdílet s přáteli na sociálních sítích. Jsme vděční za každé sdílení!
Napsali Stanislav a Kristina Fort.