


👋 Pokrok v AI — newsletter č. 4
Newsletter Pokrok v AI je zpět a přináší vám mix novinek z technického vývoje AI i světa AI regulace. Nyní již v autorském duu Stanislav a Kristina Fort.


Vítejte ve čtvrtém vydání našeho newsletteru Pokrok v AI, ve kterém shrnujeme nejnovější poznatky a vývoj v oblasti používání umělé inteligence (AI), strojového učení (ML) a AI policy a regulace.
😮💨 Konec prompt inženýrů? “Zhluboka se nadechni a přemýšlej o tom krok po kroku.”
Tým výzkumníků z Google Brain a DeepMind použil jazykové modely jako optimalizátory problémů specifikovaných v přirozeném jazyce (na rozdíl od jejich běžné specifikace pomocí matematiky nebo programovacího jazyka) a umožnil jim tak optimalizovat jejich vlastní prompty (prompt je popis toho, co po jazykovém modelu chceme, v přirozeném jazyce). Takto poté hledali optimální zadání a popisy problémů, které vedou k nejlepším řešením. Pro širokou paletu datasetů autoři ukázali, že prompty optimalizované jazykovým modelem dosahují výrazně lepších výsledků než ty navržené lidmi, a to i o 50% na obtížném datasetu Big-Bench Hard. Jak to už bývá typické, nejlepší strojem navržený prompt zní hodně pochopitelně i lidem: “Take a deep breath and think about it step by step.”
🦅 Falcon 180B je venku
Falcon 180B je venku a open source! Největší (zatím) z rodiny velkých jazykových modelů z Technology Innovation Institute v Abu Dhabi byl zveřejněn v open source formátu. Jde o jeden z největších veřejně dostupných jazykových modelů vůbec a při 180 miliardách parametrů (které by, pokud bychom porovnávali jeden parametr s jednou synapsí v biologickém mozku, odpovídaly mozkům 180 včel nebo mozku jednoho ježka či křepelky) je dokonce i o trochu větší než původní GPT-3. Na rozdíl od GPT-3 byl ale trénován na 3,5 bilionech tokenů (základní jednotky vstupu jazykového modelu – jde o části textu typicky menší než celé slovo), což je výrazně více, než původní GPT-3. Toto odpovídá takzvanému Chinchilla škálovacímu zákonu (scaling law), který říká, že potřebujeme přibližně 20 tokenů na jeden parametr, abychom získali optimální poměr cena/výkon při tréninku.
Za poslední rok se open source jazykové modely výrazně zvětšily a zlepšily a je možné, že rozdíl mezi nejlepšími closed source a open source LLMs se bude dále snižovat. Jde o nebezpečnou proliferaci nebo pozitivně laděnou demokratizaci? Jen čas ukáže. Na výkony GPT-4 ani Claude-2 ale zatím Falcon 180B zdaleka nedosahuje. Dalším potenciálním problémem pro nás Evropany je to, že Falcon pochází z Abu Dhabi a je další z čím dál viditelnější a jasnější linky ztráty naší evropské AI suverenity. Výběr dat a trénink jazykových modelů totiž není hodnotově neutrální a proto je podle mě extrémně důležité vytvořit a podporovat domácí výzkum a vývoj v oblasti těch nejsilnějších umělých inteligencí.
🧠 Mají AI systémy vědomí?
Budou mít nebo mají dokonce už teď AI systémy vědomí? Nejspíše ne, ale je to (pro většinu lidí nepřekvapivě) velice obtížná otázka. Nový článek velkého množství AI vědců a filosofů, kteří se této otázce aktivně věnují, popisuje v detailech různé aspekty tohoto problému a indikátory, které by v různých systémech mohly značit přítomnost vědomí. Jejich závěr? “Our analysis suggests that no current AI systems are conscious, but also suggests that there are no obvious technical barriers to building AI systems which satisfy these indicators.” Česky, stručněji a parafrázovaně: Dnešní AI systémy vědomé nejsou, ale nevidíme očividné technické bariéry k tomu, aby budoucí systémy vědomí měly.
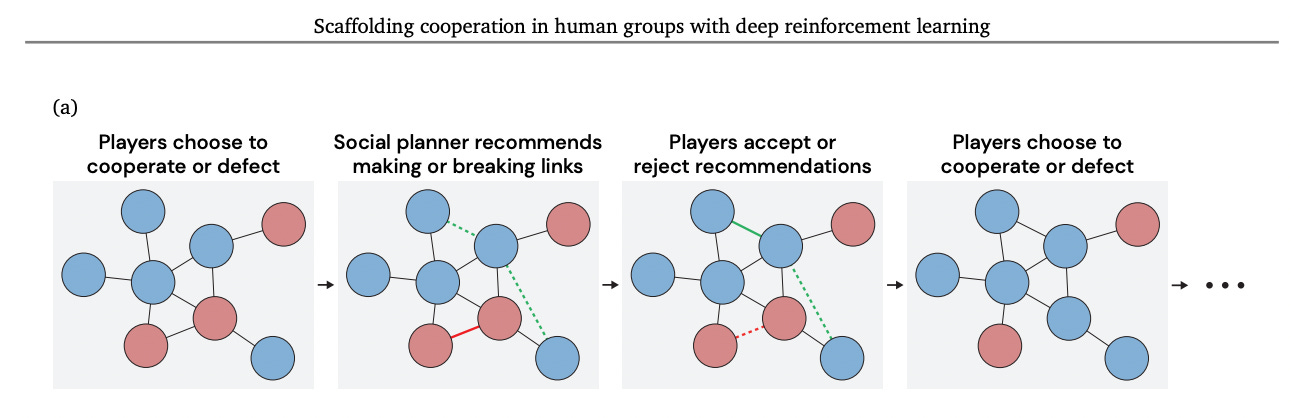
🤝 AI pro kooperaci ve skupinách lidí
DeepMind naučil pomocí hlubokého reinforcement learningu lidi lépe kooperovat. V novém vědeckém článku Scaffolding cooperation in human groups with deep reinforcement learning natrénovali výzkumníci “sociální plánovač” – umělou inteligenci, která byla schopna v rámci skupinové kooperační hry doporučovat účastníkům, aby vytvořili nebo také přerušili sociální vztahy se svými spoluhráči. Tím tento systém efektivně měnil strukturu skupin, které v této hře soutěžili a byl schopen zvýšit průměrnou úroveň kooperace na 77.7 % z původních 42.8 % bez jeho pomoci. Tento výsledek je ukázkou toho, že umělá inteligence by v budoucnosti mohla efektivně pomoci s komplexními koordinačními problémy světa (a přispět k porážce onoho eluzivního ale všudypřítomného Molocha).
📝 Je to jen memorizace? Skoro určitě ne.
Nový článek na preprintovém serveru arXiv ukazuje, že modely stylu GPT (encoder-only language models) se dokáží, i při relativně malém počtu parametrů, naučit “mentální” aritmetiku bez použití externí kalkulačky. Model o 2B parametrech (1 % GPT-3 a dokonce jen 0.1 % GPT-4) autoři naučili sčítat čísla o mnoha cifrách a dali si velmi záležet, aby ho netestovali na datech, které viděl během tréninku. Při téměř 100% úspěšnosti při mnoha ciferném sčítání oproti 4,3% úspěšnosti pro 1000x větší GPT-4 nám autoři demonstrují, že velké jazykové modely určitě nejsou jen hloupými memorizátory příkladů, které viděli během tréninku, ale že k tomu, aby správně predikovali další token při limitované kapacitě jejich paměti potřebují destilovat z tréninkových dat obecné vzorce.
🇬🇧 Velký summit nebo velký propadák?
V listopadu by se měl ve Velké Británii konat první velký světový summit zaměřený na bezpečnost AI. Tuto akci chce britská vláda využít ke znovupotvrzení své pozice “lídra” v oblasti umělé inteligence. Obestírají ji ale mnohé pochybnosti, ať už se jedná o nedostatek času na kvalitní přípravu takové akce či mezinárodní neshody kolem pozvánky pro Čínu. Byť už se vyjasnilo, že termín summitu je stanoven na 1.-2. listopadu, bude se konat v Bletchley Park u Londýna a Čína pozvánku obdrží i přes protesty některých britských spojenců, vývoj kolem této akce určitě bude stát za sledování a v tomto newsletteru ho určitě znovu zmíníme. Zatím si můžete více o záměrech britské vlády pro tuto akci přečíst zde.

🇪🇺 Dotažení evropského Aktu o AI se blíží?
Hlavní unijní iniciativou zaměřenou na regulaci AI je Akt o AI, k němuž svou pozici v červnu schválil Evropský parlament. Akt o AI se tak konečně dostal do tzv. trialogu, což znamená vyjednávání mezi Evropskou komisí, Evropským parlamentem a Radou EU o jeho finálním znění. Pozice jednotlivých aktérů a jimi navrhované formulace jsou rozepsány v tomto dokumentu, který má aktuálně přes 600 stran. Radu EU ve vyjednávání zastupuje předsednická země, jíž se v červenci 2023 stalo Španělsko. Pro španělské předsednictví je prý uzavření dohody o konečné podobě Aktu o AI hlavní prioritiou a rádo by jednání uspíšilo tak, aby v prosinci 2023 byla finální dohoda na jeho podobě. O tom, jak se jeho ambice podaří naplnit a zda v prosinci 2023 opravdu bude finální dohoda na znění Aktu o AI, se tu rozhodně ještě rozepíšeme.
🇨🇳 Nejdřív regulace, potom AI
Čínská společnost Baidu minulý týden zpřístupnila svého chatovacího asistenta Ernie Bot, podobného americkému ChatGPT od společnosti OpenAI, veřejnosti. Tento model byl dříve dostupný pouze na pozvání. Podle zástupců Baidu za prvních 19 hodin jeho služby využilo více než 1 milion uživatelů. Kromě Baidu zveřejnily své modely další čínské společnosti, Baichuan a Zhipu AI. Toto společné zveřejnění bylo způsobeno i tím, že před ním musely všechny modely generativní AI projít bezpečnostním zhodnocením, jehož výsledky byly předány čínské vládě, a potvrzením o souladu s novými čínskými pravidly pro generativní AI.
Čína je v oblasti regulace AI velmi aktivní a její přístup je založený na přesně cílených legislativních iniciativách. Hlavními z nich jsou aktuálně regulace o doporučovacích algoritmech z roku 2021 či pravidla pro hlubokou syntézu (synteticky generovaný obsah) z roku 2022. Nejnovější relevantní regulací v této oblasti jsou pak (již zmíněná) pravidla pro generativní AI. Ta byla napsána v dubnu 2023, ale už od srpna 2023 jsou v platnosti a zavazují AI společnosti k bezpečnostním zhodnocením jejich modelů i slazení modelů s ,,čínskými komunistickými principy”.
Čínské legislativní snahy v oblasti AI vychází z Národního plánu rozvoje AI, který platí od roku 2017 a má za cíl vytvořit z Číny AI světovou velmoc do roku 2030. Mimo to Čína usiluje o vedoucí roli na poli regulace a snaží se zkombinovat kontrolu nad modely (a jejich výstupy) s tvorbou proinovačního prostředí. Vzhledem k tomu, že s tímto cílem se dokáže ztotožnit většina dalších států, je sledování čínských snah mimořádně zajímavé, byť se vzhledem k povaze tamního režimu jedná o rozdílné legislativní prostředí.
🇨🇿 Česká stopa
V Česku přes prázdniny Ministerstvo průmyslu a obchodu (MPO) sbíralo názory veřejnosti na Národní strategii umělé inteligence, která nyní prochází aktualizací. Pochází totiž z roku 2019 a neodráží tak dostatečně nové technologické trendy a výsledky technologického vývoje jako je např. generativní AI.

⚡Rychlé odkazy
Standův nový oblíbený podcast je Dwarkesh Patel’s Lunar Society. Pokud vás zajímá detailní model potenciální existenciální katastrofy způsobené rozvojem A(G)I, doporučuje dvoudílnou epizodu s Carlem Shulmanem.
Všichni jsme slyšeli mnoho o společnosti OpenAI, obzvlášť od té doby, co vypustila ChatGPT, ale málokdo ji zná zblízka. Tento článek od Wired poutavě vypráví její příběh od úplných počátků.
Líbilo se vám čtvrté vydání newsletteru Pokrok v AI? Odebírejte ho přímo do vaší emailové schránky a podpořte tím naši práci!
Můžete ho také sdílet s přáteli na sociálních sítích.
Napsali Stanislav a Kristina Fort.
 | A guest post by
|
Nemáme vlastní testy/zkušenosti s výkonem či kvalitu odpovědí Falcon 180B, avšak silně nesouhlasíme s tvrzením: Na výkony GPT-4 ani Claude-2 ale zatím Falcon 180B zdaleka nedosahuje.
Dle zpráv z LinkedInu jde o 3. nejschopnější známý jazykový model, na úrovni Palm2-large, což musí znamenat, že v ELO měřítku to nebude "zdaleka", ale nanejvýš *o kus*.
Skvělá novinka by byla, že je dostupný v Hugging Face Chat, avšak zřejmě není volná kapacita( pro neplatící uživatele).